

Google Crawl Budget : How It Works and How to Optimize It?
If in a site there are more than hundreds of pages and only a handful of them are indexed by Google, then a crawl-budget issue is signified. Crawl budget is the term that describes how many pages Googlebot is able and willing to crawl on your website at any given time. If you work on large or frequently updated sites, it is a matter of concern as it considers how your content is going to be efficiently discovered and indexed.
Correctly understanding crawl budget assists with technical fixes, site structure, and high-value pages being crawled regularly. Learn in this guide how Google determines the crawl budget, common factors that waste it, and proven tips to improve it.
What is Crawling and How Does a Crawler Work?
Crawling is a process in which the search engine, or crawler, or spider, visits a web page to scan information. Initially, the bots fetch some URLs they already know and then follow their internal links or external links on those URLs to discover new URLs on the web.
A crawler works by:
- Crawling a webpage to gather the HTML content and analyze it.
- Extracting all the links present on the page.
- Adding those links to the queue for subsequent visiting, depending on priority and limitations during crawling.
- This is repeated over and over to update the index of the search engine.
In general, Googlebot assigns different crawl priorities to various pages and sets the schedules of crawling according to attributes considered important: importance of the page, freshness, site structure, and efficiency of crawling. Crawling makes any changes to your contents for indexing and ranking; hence, crawling management is one of the most crucial processes in SEO, especially for huge sites.
What is Crawl Budget and How Search Engines Assign it?
A crawl budget represents the number of pages a search engine bot, like Googlebot, is allowed and willing to crawl on the site in a given time frame. In essence, it determines how much of your site is explored and updated in the overall site’s index. For a small website with fewer pages, crawl budget is hardly ever an issue. However, when your sites possess thousands of URLs, then you must manage the crawl budget so that all important contents are found, crawled, and indexed.
Search engines assign crawl budget based on two main factors:
1. Crawl Capacity Limit (How Much Google Can Crawl Without Overloading Your Site)
This means the highest number of pages Google spidering will examine on your website without putting pressure on your server. If your site loads slowly, crashes, or shows tons of error messages, Google will slow down visits to your pages.
Some things that affect crawl capacity:
- Site Speed: When sites are very slow or take a long time to load, Google may stop visiting them frequently.
- The Strength of Your Servers: Weak or shared servers may not be able to handle too many visits at once.
- Error messages: For the presence of any 5xx errors, one would have to observe Google backing away, not to add to its impending difficulty.
With the smoother running and faster loading of a site, the more pages that Google will be interested in crawling.
2. Crawl Demand (How Much Google Wants to Crawl Your Pages)
Crawl demand indicates the level of importance or usefulness Google assigns to your web pages. Even if your site can be fully crawled, the Google crawlers will visit only those pages that it deems worthy of checking.
Things that affect crawl demand:
- Popularity of a page: Pages that receive enormous quantities of clicks or links from other websites will be crawled more frequently.
- Content changes: If you keep posting updates or updates of preceding posts, Google will return more frequently to keep track of them.
- Low-value pages: Pages that are copied, useless, or similar to others may be ignored by Google.
Signs You Might Have a Crawl Budget Issue
In the event of websites having numerous pages but Google either not being aware of or not displaying some part of the content, there may be an issue with crawl budget. Here are some frequent symptoms:
- Fewer Pages Are Indexed Than You Have Published : If you’ve published around 500 pages and only some 300 of these pages have been indexed by Google, that means a great many of your pages are actually passed over.
- Important Pages Are Missing from Google Search : Important pages like Services, Products, or Blog that do not appear in search results could be a sign that Google is not crawling them.
- Updates Are Not Quickly Displayed in Search Results : When application of update to the page is made, for example, new content joined, or an existing headline changed, a low crawl rate may cause Google to take weeks to reflect those changes.
- Unexpected increases or drops in crawl activity, or a rise in crawl errors, could indicate a problem with your site’s crawl budget.
- Google Is Spending Time Crawling Worthless or Duplicate Pages : If Google is spending time checking these insignificant or duplicated contents rather than your main pages, the crawl budget is wasted.
- New Pages Are Not Getting Quick Indexing : If the pages you have just published are not being indexed even after a number of days, it most likely means that Google is either not crawling your site often or deeply enough.
Tools to Monitor Crawl Budget
It is always a good idea to stay aware of the crawl budget when your website has hundreds, if not thousands, of pages. And the good news is that many tools can help you monitor and better understand how search engines crawl your site:
1. Google Search Console – Crawl Stats Report
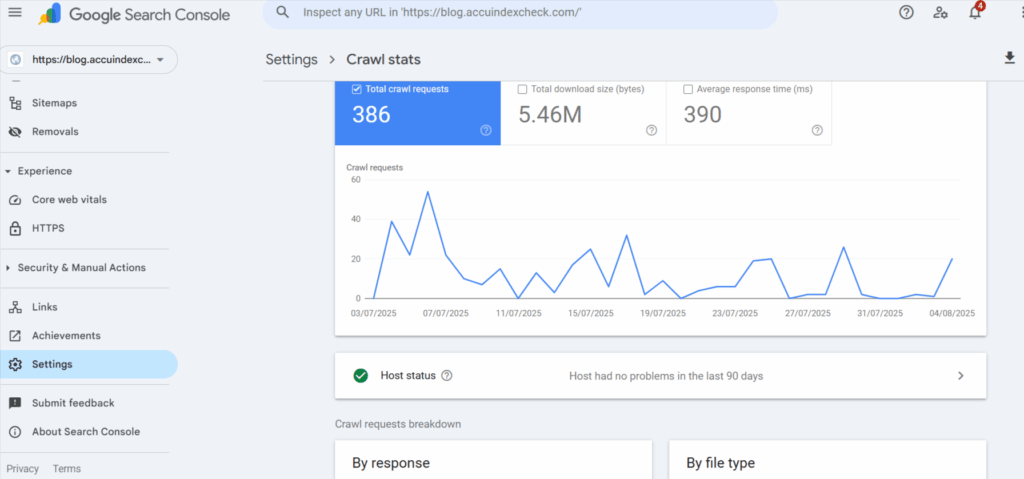
In recent years, this free tool has shown the pattern of visits of Googlebot on your site, the number of pages crawled per day, and the occurrence of any errors. There is a detailed view of the crawl-related activity ever since for the past 90 days.
How to check:
- Go to the Google Search Console.
- Click on a verified property.
- Go to Settings > Crawl Stats.
Here, you would see:
- Total crawl requests per day
- Total data downloaded
- Crawl response status codes
- Average response time
2. Server Logs
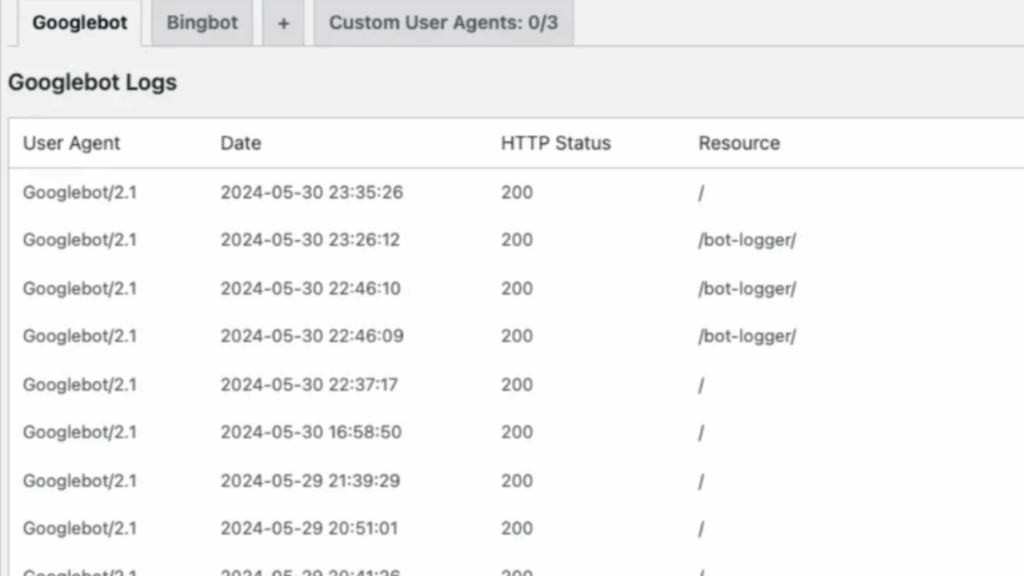
Every visit from search engine bots is noted in the server log files of your website. Analyzing such logs would tell you which pages get crawled and how many times, while helping you to figure out if Google is also wasting out its crawl budget on less-important URLs.
How to check:
- Accessing log files (mostly raw) from the hosting provider or cPanel.
- Looking for entries with user-agents like Googlebot, Bingbot, etc.
- Analyze through manual log analysis or a tool to determine:
- Pages that are crawled
- Frequency of crawling
- Patterns of crawling (e.g., if they are wasting budget on non-important pages)
3. Screaming Frog and Similar SEO Crawlers
The tool is desktop-based, and it tries to simulate search engine crawlers moving within your site. Technical issues, orphan pages, redirect chains, and duplicate content-all having potential to affect crawl budget-can thereby be detected.
How to check:
- Download and install Screaming Frog.
- Enter your URL and allow it to run the crawl.
- Review:
- Crawl depth
- Orphaned pages (include this in a paid version)
- Redirect loops
- Duplicate content
4. Log File Analyzers
Tools such as Loggly, JetOctopus, or Screaming Frog Log Analyzer sift through your server log files into readable data. They are used to inspect precisely where chill crawl budget is getting spent or in search of unnecessary URLs that may have been expending it.
How to check:
- Upload your log files into any such tool.
- View the respective dashboards that show:
- Bot frequency
- Crawled and non-crawled pages
- URLs wasting crawl budget
- Status codes such as 404s, 301s.
How to Optimize Your Crawl Budget
Your crawl budget is being improved for search engines to use their poor resources when crawling the site. The followings are key steps to ensure that crawlers spend time crawling the right pages for greater visibility and indexing efficiency.
1. Fix Crawl Errors
Such are crawl errors if the search engine attempts to load a page that does not appear properly: 404 Not Found, Server Error 500, or redirect loop stalling. Crawl errors largely waste the crawl budget since Googlebot keeps crawling the broken or useless links instead of worthy content. Delayed indexing and diminished visibility in search results are two faults that come in over time for the site.
To fix them:
- Use the “Pages” or “Crawl Stats” section within the Google Search Console.
- Put in place repairs to fix broken internal and external links or simply remove them.
- Fix server-side errors that return a 5xx code.
- Reduce or eliminate all redirect chains and loops.
- Ensure all your important pages are live and reachable at all times.
2. Optimize Site Structure
Well-structured and cleanly built site architecture promotes the crawling of content by search engine bots. If the important pages are kept too deep or not at all referenced, they likely become neglected. Proper internal linking allows the crawlers (and end users) to find and navigate to your core content smoothly. A flat site architecture-a setting wherein pages are uncloaked in just a few clicks from the homepage-facilitates both crawling and user experience.
To optimize your site structure:
- Make sure to link internally, especially deep or orphan pages.
- The most relevant content is ideally 2 or 3 clicks from the homepage only.
- Use category and tag pages responsibly to link together similar content.
- Audit your internal linking framework once in a while to keep a clean hierarchy.
3. Reduce Duplicate or Low-Value Pages
In the case of duplicate, thin, or low-value content being present, search engines might be unnecessarily wasting the crawl budget. Unnecessary pages slow down crawling for important content. By de-cluttering and merging pages where applicable, one can help Google focus on what is really important.
To reduce crawl waste:
- Add noindex tags to filter pages, tag archives, or any content that is considered outdated.
- Use canonical tags to instruct search engines about the preferred version of the duplicate pages.
- Thin content barely provides any value to users and should be deleted or merged with something more useful.
- Don’t let multiple URLs serve the same content or somewhat similar content, as it will dilute your site authority.
4. Improve Page Load Speed
When pages load slowly, search engine bots crawl the pages longer and less of your site gets indexed. A fast-loading site will facilitate coverage of more pages by Googlebots, hence with visibility implications. Speed is also important for the user experience, which indirectly argues for SEO performance.
To boost page speed:
- Use Google PageSpeed Insights or Lighthouse for speed analysis purposes.
- Serve next-gen image formats (say, WebP) for rendering big images.
- Enable browser caching, minify CSS, JavaScript, and HTML.
- Choose a hosting provider with good server response times.
5. Update and Submit XML Sitemaps
XML sitemap helps search engines in quick and efficient discovery of your important content. If it has outdated or irrelevant URLs then, it wastes the crawl budget, thereby slowing indexing. When kept clean, the sitemap would ensure that Google would index the relevant pages only.
To maintain an effective sitemap:
- Include only the URLs that are live and indexable―no noindexed, redirected, or deleted ones allowed.
- Update the sitemap as the content gets added, deleted, or its structure changed.
- Resubmit the sitemap on Google Search Console for Google to be notified of the changes.
6. Use Robots.txt Wisely
In case you don’t give proper directions, search engine crawlers may waste the crawl budget on less worthy or unnecessary pages. A properly configured robots.txt file is essential to decide which areas of your site to be crawled and which to be ignored.
To manage this effectively:
- Block all unessential sections like /admin, /cart, or URL filters that do not need indexing.
- Allow important resources such as JavaScript and CSS so that pages can be rendered correctly by Google.
- Review robots.txt periodically to ensure that some valuable things do not get blocked.
FAQs
Does the crawl budget affect rankings?
In a way, yes: If important pages cannot be crawled and indexed due to limitations of the crawl budget, they do not even show up in the search results, thereby attacking your rankings.
Can small sites ignore crawl budget considerations?
Generally, yes — most small websites do not have crawl budget issues because Google can crawl all their pages very easily. However, it is always a good idea to maintain a clean structure and fix errors.
How often does Google update crawls?
The Crawl Stats Report gets updated every few days but mostly reflects activity over the last 90 days.
What is the crawl budget limit for Google?
There is no fixed number for a crawl budget. Google sets the crawl budget for your website based on the size of your site, its health, server performance, and perceived value of your content. If your site is filled with lots of low-value pages or terribly slow-loading pages, your contents may not get the attention it deserves, and Googlebots will also reduce the crawling frequency of the site.
How do you reduce the crawl budget?
Temporary takeaway to slowdown would mean backing the 503, 500, or 429 HTTP status response to Googlebot; Crawl Rate can also be permanently hurtled in Google Search Console, but changes there require a fair bit of time to wind into effect.
In Conclusion
When it comes to technical SEO, managing your crawl budget in an efficient manner becomes crucial at bulk and complex websites. When search engines crawl and index the most valuable content of your website effectively, it leads to good visibility in search results. As you fix crawl errors, improve site structure and speed, and perform checks using Google Search Console and log analyzers, the net result seen is that Googlebot can be directed away from careless pages and onto the right pages. Regular checks with proactive changes will buoy the further search-friendliness and discoverability of your site.