

What Causes ‘Duplicate Without User-Selected Canonical’ in GSC and How to Fix It
The duplicate without user-selected canonical issue is common in Google Search Console, where Google finds multiple pages with even similar or identical content but is unclear as to which it must take into account for an index. Consequently, the ranking potential gets diluted, crawl budget gets wasted, and the search results get confused, hampering your Search Engines’s visibility.
Keep reading for a crisp check list and workable steps you can immediately apply to resolve the issue, thereby maintaining SEO performance.
Primary Reasons For ‘Duplicate Without User-Selected Canonical’ Error
Here are the main causes behind Google’s ‘Duplicate, without user-selected canonical’ report:
1. Duplicate Content Across Multiple URLs
Duplicate content occurs when one or almost identical text exists under different URLs. For example, a product page might be at example.com/product but may also exist at example.com/product?ref=affiliate. Search engines would then treat different page URLs as different pages and get confused as to which one should be indexed.
This confusion can dilute ranking signals, making it harder for the search engines to accumulate credibility onto one page. Common instances are when designers implement session IDs, printer-friendly versions, or categories that lead to different paths for the same content.
2. Parameter-Based URLs and Tracking Codes
Many websites track or filter using parameters in URLs such as ?utm_source=email or ?=color=blue. These parameters serve marketing or sorting purposes but cause distortion in URL creation-provided on multiple fronts for the same content.
Search engines consider each URL variation a separate page when it carries the same content. This leads to a greater set of duplicate pages being crawled and may hamper index efficiency while diluting page relevance.
3. Pagination and Sorting Issues
Pagination causes content to be divided into multiple pages, such as for product listings or article archives where pages exist with URLs like page=2 or page=3. The sorting facilities, such as sorting by price or sorting by popularity, also generate multiple page variations that display substantially the same information.
These variations may be seen as near-duplicate pages by search engines. At times, important content may appear deep in the sequence, making it less likely to be given preferential indexing treatment.
4. Incorrect or Missing Canonical Tags
Canonical tags deem one page better than the other and let the search engine know of that one preferred version. Search engines can end up indexing the wrong version of a page when canonical tags are not properly implemented.
This could lead to duplicate search results or outdated pages in search; additionally, search engines could be confused about the relationships involved, fragmenting ranking signals.
5. Content Syndication Without Proper Canonical Setup
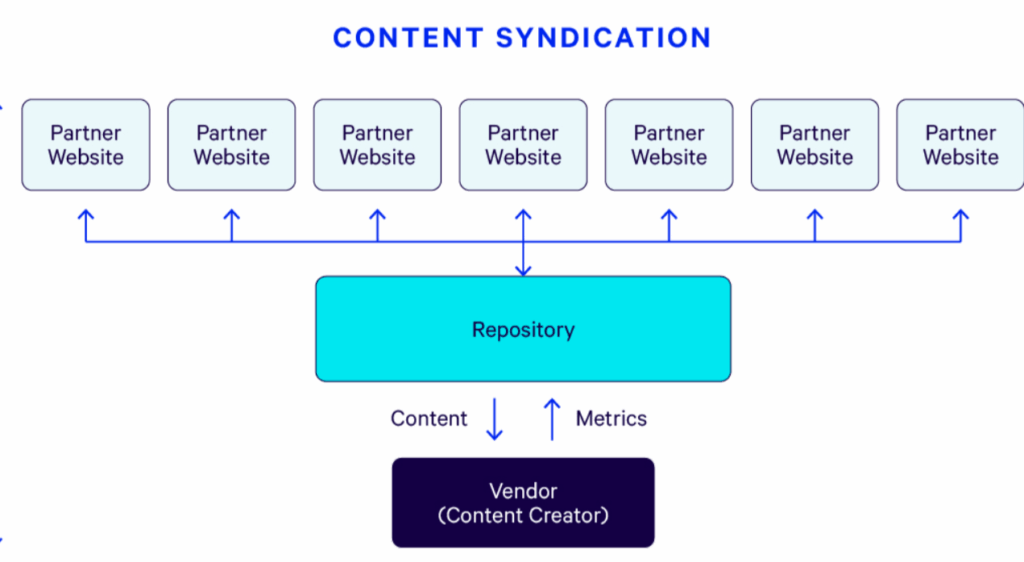
When content has been republished on another website without proper canonical attribution, search engines become confused and do not identify which is the original. This is the case with news, blogs, or partner content sharing agreements.
With wrong source identification, the syndicated version might be competing-or worse, outranking-the original in search results. Due to the lack of proper source identification, search engines might consider the original and syndicated copies as duplicates and thus might affect visibility.
How This Impacts SEO
Loss of Ranking signals Due to Split Authority
When the same content is duplicated over more than one URL, backlinks, social shares, and engagements get spread over those copies, rather than being funneled into one URL. Such fragmentation diminishes the carrying authority of a page and thereby each of those URLs becomes a weak player in search results placement.
Dispersed link equity decreases the chances of ranking for competitive keywords over a period of time as search engines are less clear about which page should be considered the authoritative result.
Possible Indexing of the Wrong Page
Under this scenario, the search engines will be deciding to index secondary URLs or parameterized URLs, which are not your primary choice, as Google seems powerless to resolve some of those confusing signals.
The cardinal problem with such indexing is that these less-optimized, duplicate, or irrelevant pages would compete with the ones you want to be ranked. This obviously confuses the users as they land on these tracking or session URLs really, thereby baffling you when it comes to meta tags, structured data, or content updates because the outcome in visibility is not the canonical one you yourself maintain.
Negative Effects on Search Visibility and Traffic
These pages make the search engine system crawl more, and they set noise in the index, reducing the rate at which the engines crawl your important pages. Dilution of ranking signals and lowering crawl efficiency generally leads to lowering organic visibility.
In return, traffic drops—not because demand is actually falling but because the site is unable to signal an optimum level of relevance and authority to search engines, hence triggering less discoverability of its valuable pages.
Fixes for “Duplicate Without User-Selected Canonical” in Google Search Console
Having undergone these targeted fixes, authority consolidation can occur, duplicate signals may diminish, and clear indexing signals may flow to a most important page:
1. Add or Correct Canonical Tags
Canonical tags notify search engines about the particular page desired for indexing in cases where several variants exist, and without these tags, search engines may very well opt for their own judgment, which could well not be the one you have optimized. An implementation correctly done guarantees a consolidation of all ranking signals to your preferred URL.
How to do:
- Ensure every indexable page contains a self-referencing canonical tag to tell Google it’s the authoritative version. Place this within the section, ensuring it matches the final resolved URL exactly.
- Always use absolute URLs in the proper format, which contains the protocol, that is, https://, the domain, and the correct path, without unnecessary URL parameters unless there is a truly necessary distinction for unique content.
- Avoid canonicals pointing to non-indexable or redirected pages as these contradicting signals might let Google ignore the tag.
- Auditing your canonical tags and verifying them with tools such as the URL Inspection tool within Google Search Console or perhaps a site crawler would be a good idea to ensure that the intended URL is the one chosen by search engines.
2. Consolidate Duplicate Pages
Creating many pages all sharing the same or similar information causes these pages to compete against each other in rankings, thus diluting authority. Fewer more valuable pages will benefit rankings and will relieve the user from going through unnecessary pages.
How to do:
- Check for duplicated and near-duplicate pages by using SEO audit tools for content similarity and index overlap.
- Merge related contents into one big authoritative page by selecting feasible parts of these duplicates, extracting, reorganizing, and optimizing them into clear SEO nouns.
- Retain the best URL alive, i.e., that with the greatest number of backlinks on the authority side or competition on traffic and current keyword ranking.
- Expectedly, all internal links, menus, and sitemaps that previously pointed to any of those copied pages finally change to the one remaining, so users and crawlers always land on the right one.
3. Adjust URL Parameters in Google Search Console
URL parameters used for tracking, sorting, or filtering can create hundreds of superfluous variants that consume the crawl budget and confuse search engines. Google Search Console has the URL Parameter tool that allows you to control the crawling and indexing of such variations.
How to do:
- List all parameters in use (e.g., utm_source, color, sort), weigh whether they alter the actual content of a page or merely follow user behavior.
- Set crawling preferences in the URL Parameters tool, never crawling parameters that do not change content (for instance-a tracking code).
- Do record your settings to give future team members an understanding of why certain parameters are not crawled.
- Keep track by monitoring index coverage reports and crawl stats in Search Console after having made the changes, to ensure that important pages are not affected, but that the duplicate clutter is minimized.
4. Use 301 Redirects Where Needed
301 redirects permanently transfer user agents and search engines from their duplicate or obsolete URL to the preferred one, thus passing nearly all of the ranking signals. They are key in avoiding any loss of SEO value when pages are deleted or merged.
How to do:
- Go through the menu, breadcrumbs, and content to audit all the internal links so as to locate links to any parameterized or outdated versions.
- Replace links pointing to non-canonical URLs with links of the exact canonical versions to ensure consistency across the site.
- Verify the dynamic links generated through faceted navigation or filters, possibly also by tracking scripts, to confirm if they indeed point to the correct URLs.
- Don’t allow redirect chains and redirect loops by redirecting each duplicate URL directly to the real URL rather than to an intermediary one.
5. Update Internal Links to Point to the Canonical Version
Even with proper canonical tags, internal links that point at non-preferred URLs can mix the signals sent out to search engines. Constant linking to the canonical one strengthens the notion of which page should be indexed and ranked.
How to do:
- Perform an audit on all internal links in the menus, breadcrumbs, or within the content to look for the parameterizing or outdated versions of the site.
- Further, non-canonical links must run replaced with their true canonical URL for consistency throughout the site.
- Double-check dynamic links-generated through faceted navigation, filters, or tracking scripts-to make sure they point to the proper URLs.
- Update and resubmit your sitemap after making any changes to your linking so that Google can find and prioritize the canonical versions fast.
6. For Syndicated Content, Use Cross-Domain Canonical Tags
When your content gets copied and appears on a different domain, search engines might end up considering the partner’s copy as original unless told otherwise. Cross-domain canonical tags preserve content authority and its rankings.
How to do:
- Syndication partners’ pages must contain a cross-domain canonical tag pointing to the original URL so that search engines may know which page to index.
- Where such canonical tags cannot be applied, ensure that there is a clear, clickable attribution link, preferably placed near the top of the syndicated article.
- The original version should be published first so that it can get crawled and indexed before the partner copies go live.
- Double-check the partner pages at regular intervals by viewing the source code to ensure the canonical tag is applied correctly and points to the exact protocol, domain, and path.
FAQs
How to fix duplicate submitted URL not selected as canonical?
Identify duplicate pages, select a preferred one, and assign the correct canonical tag. Then, update internal linking and sitemap to point to the selected version.
What does duplicate without user selected canonical mean?
It means, Google detected two or more duplicate pages but the webmaster has not stated a preference as to which page is considered canonical; hence Google may be choosing one canonical page itself.
How to fix duplicate without user selected canonical in Blogger?
Edit the Blogger template to include canonical tags, remove duplicate URLs of posts, and ensure that the permalink settings are consistent.
What can be done to eliminate duplicate content on my site?
Remove or merge duplicate or similar pages. Use canonical tags and 301 redirects and do not publish the exact pages on two different URLs.
What happens when the canonical tag is not found in the website?
Google may choose its own preferred page version, thus resulting in undesired indexing and possible SEO ranking issues.
In Conclusion
The presence of such “duplicate without user-selected canonical” issues brings clarity to crawlers, concentrates ranking signals on their highest-value pages, and allows these pages to be overtaken by duplicates. The fixes must be implemented consistently—fix canonicals, consolidate content, control parameters, use redirects, and align internal links—and then the indexing and performance must be monitored to confirm improvements. This is a continuous process: conduct follow-up audits, document the changes, and iterate to sustain clear search visibility for your site.