
How to Identify, Address, and Fix Duplicate Content Issues for Better SEO
Duplicate content is one of the issues that webmasters mainly have to deal with and it can be a never-ending problem which can result in a negative impact on the search rankings, along with link authority loss and an unpleasant user experience on the site.
The concern can be that the content manager could be unable to handle the issue all alone. Sometimes, the technical errors lead to duplicate content and in such cases, a system thoroughly looked into and a very smart approach applied might be what it takes to finally get the problem solved.
The emphasis is put on the elimination of duplicate content through identifying its origins and at the same time giving practical solutions and suggesting strategies that can be employed in a gradual manner, thus enabling you to eradicate the nuisances and also warrant the non-duplication of the overall SEO performance of your site.
What is Duplicate Content?
Duplicate content refers to website portions, either text, whole pages, or even the entire website that are present or accessible at two different locations on the internet. One location may be your website, and the other may belong to a different site. In such a scenario, the search engines will get confused and won’t really know which page should be ranked higher thus, showing it in the search results.
Unintended duplicate content is a common occurrence throughout the web. To name a few, printing-friendly pages, URL parameters, and session IDs along with content syndication are some of the causes that may produce duplicate content. While little duplication might not cause any problems, however, large or uncontrolled duplicated content can make your site less searchable, divide link equity between the pages and confuse both the users and the search engines.
Why Is Duplicate Content An Issue?
The issue that is very similar to duplicate content and has the same impact is the fact that it confuses the search engines and they do not know which page to show in the search results. The fact that such pages with identical content exist might not be detected by the search engines, thus not the most relevant version being ranked, which may lower the site’s overall visibility instead.
In addition, the search engines will distribute the SEO value, so called, Link Equity Dilution, among the pages which is one of the situations where backlinks point to multiple pages with similar content, the pages will lose the whole SEO value as it gets divided among them.
For the users, duplicate content is a source of the poor experience. The website visitors may find the information very similar and their trust in the website may eventually be lost.
The situation is worse since it also has a negative impact on the site in terms of search engine perception. Such sites may be branded as low-quality because of large duplication and in turn, their rankings would be curtailed, eventually leading to less traffic and a gradual effect over time.
In conclusion, the management of duplicate content is imperative for both the SEO power retention and the good user experience delivery.
How Does Duplicate Content Impact SEO?
Duplicate content would actually be the greatest downfall for SEO. If there exist several web pages within one site that are alike or at least somewhat different in their content, the search engines might get confused as to which one is to be recognized as most important. Owing to this, rankings go down while visibility suffers a blow, and all the SEO efforts go in vain.
Here are the main ways duplicate content affects SEO:
- Lower Search Engine Rankings: When it comes to duplicate content, the search engines might show only one version of the content and as far as the positioning of other versions is concerned, they would be sent down even though they have value, thus the visibility of the whole site decreases.
- Diluted Link Equity: “Link equity” signifies the portioning of SEO value among different versions of the same content that have been linked from different sources. Hence, rather than one page getting full authority, the SEO value gets shared which makes it more challenging for your page to attain high rankings.
- Reduced Crawl Efficiency: Search engines assign a crawl budget to every site, which is the total amount assigned to crawling The duplicate pages utilize this budget and hence the unique and important pages are left with fewer resources for indexing.
- Penalty Risks : It is not common to see a website being punished solely due to duplicate content. If one major chunk of the text goes inefficient, the complete site might have been considered inferior or spam, which naturally dampens the worth of the website and its ranking.
- Negative User Experience : When repetition of the same content happens for the users, boredom sets in, irritation grows, and they finally leave the site, which then indirectly affects SEO.
Common Causes of Duplicate Content Issues
There is always been and continues to be the issue of duplicate content for most websites, which can be initiated by either internal factors or external factors. It would be really nice to spot the signs in this case because then the matter will be dealt with very efficiently.
Internal Causes
- URL Parameters : In some scenarios, URLs get parameterized (like example.com/product?color=red), and such scenarios are seen mainly when traffic monitoring, page categorization, or filtering is the reason. A major disadvantage of this is the generation of duplicate content that is often a by-product of the original main page.
- www vs. non-www or HTTP vs. HTTPS : The search engines, in case of no canonical redirection, will consider the two versions of the website (one with www and one without; or one with HTTP and one with HTTPS) as separate pages that have the same content. They are treating each version as a different one, but with identical content.
- Category and Tag Pages : Many content management systems (CMS) such as WordPress provide this opportunity, where it is up to the users whether to create category and tag pages or not. However, if these pages are not managed properly, there may be internal duplications through the same posts showing more than once.
- Printer-Friendly or Paginated Pages : The content made for printing may be the same as the content of the main page or the paginated page. The scholarly nature of duplication in this case often leads to duplicate content.
- Session IDs and Tracking Codes : Dynamic websites may provide different URLs for the same page according to the session, and e-commerce may be the cause of the recognized content issue.
- Duplicated Content Across Your Own Pages : When the same product description, blog introduction, or service details are repeated across multiple pages without any modifications, internal duplication can occur.
External Causes
- Content Scraping or Plagiarism: A possibility may be that other websites copy your content without your permission and make duplicate copies. It is totally out of your control but it could even result in less visibility of the content since the copied one might attract more viewers than the original one which, thus, creates confusion regarding its originality.
- Syndicated Content : In the case that the content shared with sites like Medium, LinkedIn, or guest blogging, then the duplicates may occur unless proper attribution or canonical tags are applied.
- Press Releases Copied Across Sites : It is a usual practice to distribute press releases in various media and that increases the chance of having identical content on different domains.
- Third-Party Widgets or Feeds: The use of third-party content through feeds and widgets may cause your website to unintentionally display duplicate content.
- Affiliate or Manufacturer Content: Most e-commerce sites get the product descriptions directly from the manufacturers which can lead to the same content across several sites. If it is not reworded or optimized, a large duplicate content problem can be created.
How to Identify Duplicate Content
Duplicate content not only brings about difficulties but also user awareness adds to the effort. However, amongst the various techniques to optimize at least the search engine optimization SEO is to remove duplicate content. In case of internal or external duplicate content, the pages may get ranked lower in the search engine results; hence, the capacity to detect them will be extremely beneficial. There are various methods and tools for the accurate identification of these problems.
Manual Checks
Manual checking for duplicate content may only catch the most apparent cases. For instance, take a sentence or paragraph that you think is original, put it in Google with quotation marks around it and find out if the content on your site is the same or different. Also, looking at the URLs and the page titles may give you hints of duplication if there are pages with similar names or URL parameters.
SEO Tools
The use of tools will make the entire procedure quicker and at the same time, it will be more exact.
- Screaming Frog SEO Spider:This tool will conduct a thorough crawling of your website to identify pages containing the same meta descriptions, content, or titles as others.
- Copyscape : This tool will let you know if your content has already appeared on other sites. It is very useful for plagiarism as well as content sharing detection.
- SEMrush or Ahrefs Site Audit : They will create reports that specifically deal with duplicate pages, meta tags, and titles.
CMS and Technical Checks
Meta title and description should be the same for page versions, but this is not always true because these have duplicate issues. Using canonical tags correctly that are aligned and point to the right page is yet another method to eliminate internal duplication.
Analytics and Crawl Reports
With Google Search Console, you will receive notifications about the areas that need improvement in terms of the titles, descriptions, and indexing. The crawling of your website at regular intervals can uncover duplicate content that is hidden due to URL parameters, session IDs, or printer-friendly pages.
External Content Checks
The awareness of content scraping or unauthorized syndication can prevent the situation of duplicate content on the other sites that rank higher than your original pages. Accordingly, these tools become invaluable for plagiarism searching.
How to Address and Fix Duplicate Content Issues
Once the duplicate content is detected, the following step will be to recommend the suitable way of disposing of the duplicates. The correction of the content will not only enhance but also maintain the ranking of the site and visibility in search engines, create a better user experience, and preserve link equity. Following is a list of the best practices that can be adopted as means to cope with duplicate content:
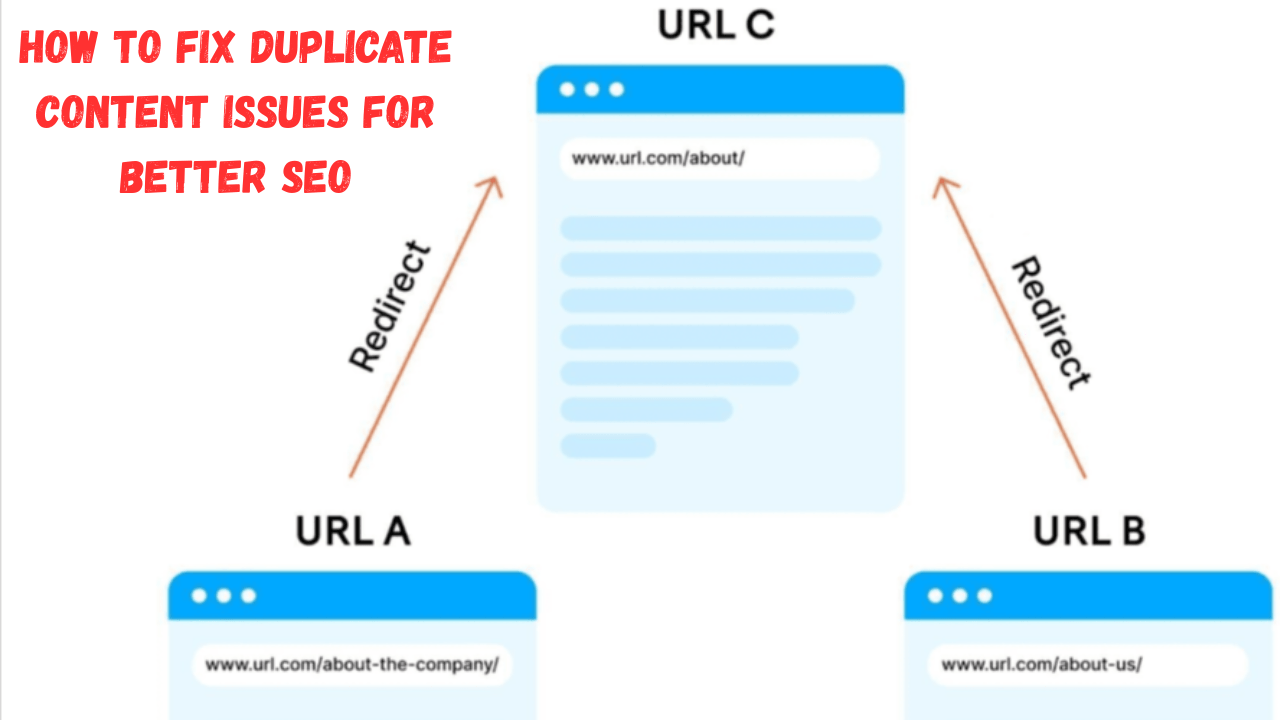
Implement 301 Redirects
The 301 redirect is the method of permanently redirecting both users and search engines from one URL to another while simultaneously merging the similar pages into one main page. It ensures that all the link equity is transferred to the chosen page.
Example : When you have two similar pages at example.com/product-red and example.com/product-blue, redirect the less important page to the main product page.
Use Canonical Tags
The canonical tags (rel=”canonical”) are actually used in guiding the search engines to which page is the most important one. Another way this plays out is by letting users get to all editions.
For example, an ecommerce store may have single product multiple URLs on account of filters and categories being applied, but it can still canonicalize to the main product page.
Use Noindex Tags
With noindex tags, the search engines will be able to cease the indexing of low-quality and duplicate pages. This is especially applicable for user-friendly pages that should possibly not be competing in search results.
Example: Noindex can be used on category pages, tag pages, or printer-friendly versions to make sure that these pages do not get regarded as duplicates.
Merge or Rewrite Content
The best option may be rewriting when there are several pages with similar content. You can even choose to do it in such a way that each page is unique or you would like to combine all pages into one comprehensive resource. Not only can you enhance User Experience but also assign SEO for each page.
Example: You can merge two blog posts on closely related topics into one comprehensive guide that incorporates updated information.
Keep a Uniform Structure for Your URLs
Inconsistency between www. and non-www., or HTTP and HTTPS, can make room for duplicated URLs, and these are the one you want to avoid. Instead, have a practice that redirects all the variations to the single and consistent URL structure of your site.
For example, it is critical to avoid page version conflict; hence, all the traffic to http://example.com and www.example.com should be directed to https://example.com.
Regular Content Audits
Website regular audit will be the basis for quick detection of the duplicates. After discovering pages that are duplicated or similar in terms of title, meta-description, or content with tools such as Screaming Frog, SEMrush, or Ahrefs, you eliminate the duplicates through the method listed above.
Conclusion
Duplicate content brings SEO considerations along with some user experience grievances. You should avoid troublesome content by applying consistent redirects or canonical tags, being able to noindex them, or simply editing them. In most cases, this has an amazing effect on search rankings, site authority, and user experience. If you want to prevent future problems, make conducting an audit and applying the best treatment regimen part of your working practice.
FAQs
What are the effects of duplicate content in SEO?
Duplicate content confuses search engines as to which page is the correct one for purposes of ranking and works to reduce visibility of the search. Also, it bifurcates link equity among pages and hence stands in opposition to the authority of your site, which then reflects back on its SEO performance.
How much duplicate content is allowed?
Slight duplication of content with disclaimers, header, or footer text is quite normal. However, any mass duplication-type content will be detrimental to search rankings and the human experience-the kind of dupe content that should be avoided at all costs.
How to identify duplicate content issues?
Various SEO tools can detect duplicate content, such as ScreamingFrog, Semrush, Ahrefs, and Copyscape. A manual search can also reveal some duplication: You take one or two lines from your page, put them inside double quotation marks, and put those same words in a Google search to find copies internally or externally.
How to resolve duplicate content issues?
Some of the popular resolving methods would involve merging similar pages through 301 redirects, setting canonical tags to signal the preferred version, setting low-value pages to noindex, either altering or merging the content, and ensuring that all other URLs referred to from within the site follow the same URL structure.
How do you report duplicate content?
If a site has stolen your content, those sites can be reported to Google through the copyright complaint form. In cases of internal duplicates, one can use URL manipulations and index settings using Google Search Console to have only the chosen pages shown.